認識 Google Analytics的『取樣數據』- 初學者篇
 圖片來源:unsplash.com、Harris先生提供
圖片來源:unsplash.com、Harris先生提供
舉例來說,如果你想知道台灣人口的2300萬人的行為資料,但2300萬人的資料過於龐大、處理起來會花費更高的成本與時間,因此你取了20%的460萬人口來做分析、理解他們的行為,並用這20%的人口樣本做為參考來理解整個2300萬人,在概念上,20%的取樣必須包含所有可能影響到資料的族群特徵,比方說這20%的取樣裡面必須包含所有的年齡層、性別、生活型態,這就是所謂的取樣數據。題外話:前幾個月因Harris在撰寫Google Analytics的書籍(預計2017年底前出版),所以文章有一段時間沒有更新,從九月初開始我將回來部落格繼續撰寫每週一篇的文章~,大家敬請期待。
Google Analytics的取樣數據可能對你的分析工作造成傷害
Google Analytics裡面一樣會有取樣數據的狀況,雖然取樣數據能夠讓整個分析過程加速進行、並具備高效率的特徵,但取樣數據的問題在於,你所得到的資料並不會是絕對精準,有極大的可能你所看到的取樣資料,與沒有被取樣到的資料具備著完全不同的特徵與結果。
如下圖,從Google Analytics報表的右上方我們可以看到該報表是否有被取樣(幾乎所有的報表右上方都會有這個欄位),上面會顯示“這份報表是以xx%的工作階段來計算,只要這裡顯示的不是以100%的工作階段來計算,就代表你當下正在看的報表,是有取樣數據的問題。
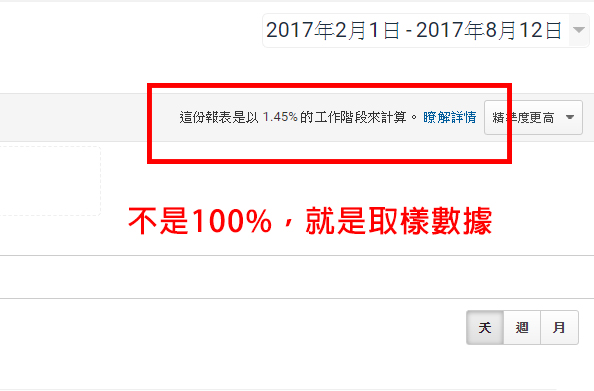
在網站分析上取樣數據並不是一件有正面影響的事情,因為這代表你看到的資料並不精準,尤其當你要計算網站收益、廣告成效這些重要指標時,取樣數據更可能錯誤的影響你的決策。
Google Analytics的取樣數據如何運作
Google Analytics在收集資料時,會先將資料整理、運算好,並預先儲存到資料庫裡面,當你在使用預設報表時(像是目標對象、客戶開發裡的預設標準報表),Google Analytics因為已經把這些資料提前運算並整理好,所以你可以在很短的時間內看到數據報表(Google Analytics的數據這麼龐大,但還能一點報表就立刻跑出數據,就是這個原因)。
但如果你今天使用了次要維度、或進階區隔來篩選出客製化的資料,因為Google Analytics並沒有預先把你要的資料運算好,為了加速報表呈現給你的速度,它就會取樣部分的資料來運算你的需求給你,這當然也是為了更快地呈現出報表。